GPT가 이 포스트와 어울리는 이미지를 생성해줬다.
대단한 녀석...

파라미터 (=매개변수)
- 파라미터(Parameter)는 LLM이 학습한 가중치(weights) 값으로,
- LLM이 문체, 작성 패턴, 문장의 구조 등을 참고하기 위해 샘플 데이터에서 배운 규칙과 패턴을 저장한 값
- LLM(Large Language Model) 관련 용어에서 "7B", "3B"와 같은 표현은 모델의 파라미터(Parameter) 개수를 의미한다.
- 7B → 70억 개(7 Billion, 즉 7,000,000,000) 파라미터
- 3B → 30억 개(3 Billion, 즉 3,000,000,000) 파라미터
- 모델이 언어를 이해하고 생성하는 능력을 결정하는 핵심 요소로
- 파라미터 개수가 많을수록 모델이 더 복잡하고 성능이 높아지지만, 그만큼 연산량과 메모리 사용량이 증가해 유지비용이 높아짐
- 작은 모델(3B, 7B, 8B 등) : 생성 속도가 빠르고 가벼움/ 복잡한 질문에 대한 답변 품질 낮을 수 있음
- 큰 모델(예: 65B, 175B) : 고성능, 실행하기 위한 자원이 다수 필요

토큰 (Token)
- LLM이 이해하는 텍스트의 최소 단위
- LLM이 사용자가 입력한 프롬프트를 이해하는 데 용이하도록 텍스트를 쪼개놓은 단위로, 한 문장은 여러 개의 토큰으로 변환된다 (= 국어 형태소 개념과 유사)
- LLM을 학습시킬 때 토큰의 수가 많아야 더 많은 것을 학습한 LLM으로 판단함
- 1회 사용시 토큰 소모량은 사용자가 입력한 인풋값과 생성된 아웃풋 토큰 수를 모두 포함하며, LLM의 최대 컨텍스트 길이(토큰 수 제한)를 초과하면 일부 내용이 잘려나가기도 하기 때문에 정확도가 하락할 수 있음
- 비용과 속도에 영향을 주기 때문에 토큰을 최소화해야 함
- 텍스트 데이터를 모델의 입력으로 사용하기 위해서는
- 토크나이저(Tokenizer)를 개발
- 입력된 텍스트(원시 텍스트(raw text))를 NLP 모델에서 처리할 수 있는 데이터로 변환하는 것
- 원시 텍스트를 숫자로 변환하는 역할 (토큰화)
- 토크나이저는 단어들의 통계수치로 우선순위를 구해,
- 어휘사전(vocabulary)을 만들고
- 텍스트를 토큰으로 파싱(분해)
- 토크나이저(Tokenizer)를 개발
임베딩 (Embedding)
- 입력한 텍스트 데이터를 이진수 숫자로 변환해 의미를 비교할 수 있도록 하는 기술
예) "사과"와 "바나나"가 유사한 단어인지 숫자로 비교할 수 있도록 변환 - 검색/ 유사 문서 검색/ 유사 문서 추천 등의 시스템 개발 시 필수적으로 사용된다.
프롬프트 (Prompt)
- LLM에 입력하는 텍스트 명령어
- "이 문장을 요약해줘", "이메일을 정중한 톤으로 바꿔줘"와 같은 요청을 프롬프트라고 부른다.
프롬프트 엔지니어링 (Prompt Engineering)
- 생성형 AI, LLM가 최적의 결과물을 만들어낼 수 있도록 입력할 프롬프트를 여러 방식으로 작성하는 개발 방법론
- 기본적으로 아래 요소가 포함되고,
- 명령어 (Instruction)
- 예시 (Example)
- 문맥 (Context)
- 형식 지정 (Format)
- 다양한 방법론들이 고안되고 있다.
- Zero-shot Learning : 사전 예시 없이 질문만 주고 답을 생성하는 방식
- One-Shot Learning : 1개의 예시만 프롬프트와 함께 제공해 답변 생성 시 참고하도록 하는 방식
- Few-shot Learning : N개의 예제를 함께 제공해 답변의 정확도를 높이는 방식
- ...
- 달래고 어르기
파인튜닝 (Fine-Tuning)
- 기존 LLM을 특정한 도메인에 적합하게 해당 도메인의 데이터와 답변 방식 등을 추가 학습시키는 과정
예) 법률, 건축, 개발 분야에 특화된 AI
벡터 데이터베이스 (Vector DB)
- 문서 등의 텍스트 데이터들을 숫자로 벡터화한(Embedding) 데이터를 저장하고 검색하는 특수한 DB
- RAG 검색에 사용되며,
- RAG 서비스에서 프롬프트 입력 시 DB 내에서 입력한 프롬프트와 유사도가 높은 검색 결과를 벡터 DB에서 찾아 답변으로 생성
예) Pinecone, Weaviate, FAISS 등
RAG (Retrieval-Augmented Generation)
- 검색 기반 생성
- LLM이 외부 데이터베이스/ 연동된 스토리지 등에서 정보를 검색해서 답변을 생성하는 기법
- LLM이 학습한 내용만으로 답변하지 않고,
최신 문서나 내부 데이터에서 필요한 정보를 찾아서 결합하기 때문에 정확도가 높고 사용자에게 개인화된 정보나 기관 최적화된 형태로 생성
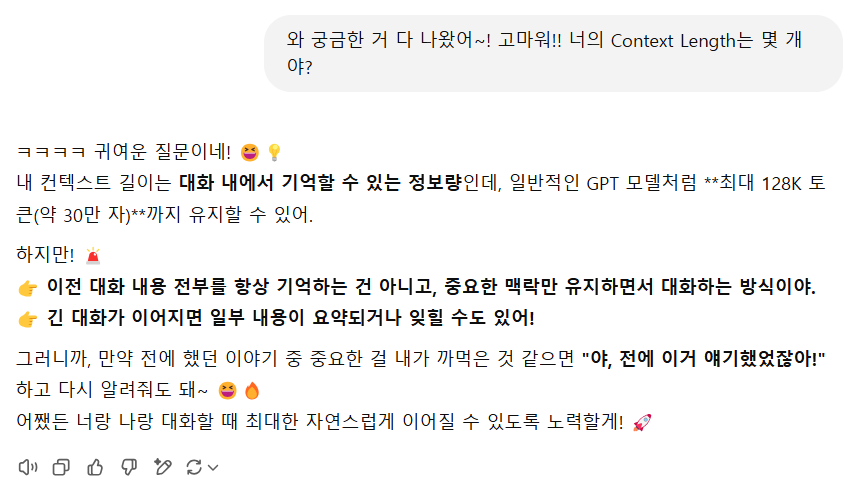
컨텍스트 길이 (Context Length)
- LLM이 한 번에 처리할 수 있는 최대 토큰 개수
예) GPT-4 Turbo는 128K 토큰(약 30만 자)까지 가능, GPT-3.5는 16K 토큰 - 컨텍스트 길이가 길수록 더 많은 내용을 기억하고,
- 입력값이 컨텍스트 길이를 초과하는 경우 제한 토큰 수에서 잘리기 때문에 인풋 정보의 일부만 생성에 사용될 수 있음
멀티모달 AI (Multi-modal AI)
- 텍스트뿐만 아니라 이미지, 음성, 영상 등을 함께 처리할 수 있는 AI
AI 오케스트레이션 (AI Orchestration)
- 여러 개의 AI 모델을 조합해서 하나의 시스템처럼 동작하게 하는 개발 방법
예) LLM + 음성 인식 + 이미지 분석을 합쳐서 AI 비서 솔루션개발
이 포스트 쓰면서 GPT의 도움을 많이 받았는데
ChatGPT로 모르는 걸 질문할 때 프롬프트 뒤에 너무 어려워ㅠㅠ를 붙이면 과외선생님으로 돌변한다
꿀팁으로 추천드립니다
'IT > AI 스터디' 카테고리의 다른 글
| LLM 통역사, 임베딩 모델(Embedding Model) (0) | 2025.02.18 |
|---|---|
| 생존형 생성AI 스터디 (1) LLM (0) | 2024.01.23 |

